
Продолжим нормализацию и попробуем привести некоторые таблицы к 3НФ, для начала приведу определение 3НФ, НФБК а также те определения и примеры которые считаю важными (далее цитаты из книги Дж. Дейта):
Третья нормальная форма
3НФ - переменная отношения находится в 3нф тогда , когда каждый кортеж состоит из значений первичного ключа и множества независимых атрибутов (неключевых), в кол-ве от нуля и более некоторым образом описывающих сущность.
(в определении передполагается наличие только одного потенциального ключа, который является первичным ключом)
Переменная отношения находится в 3нф тогда , когда она находится во 2й нф и ни один неключевой атрибут не является транзитивно зависимым от ее первичного ключа (под эти подразумевается отсутствие в переменной отношения транзитивных зависимостей). Это означает что в ней отсутствуют какие либо взаимные зависимости в указанном выше смысле
Второй этап нормализации состоит в создании проекций для устранения транзитивных зависимостей (когда одни данные могут быть получены через другие) Пусть есть * R {A,B,C} PRIMARY KEY {A} (предположим есть зависимость B->C (CITY->STATUS)) Процедура нормализации передусматривает замену переменной отношения R следующими двумя проекциями R1 и R2 * R1 {B, C} PRIMARY KEY {B} * R2 {A, B} PRIMARY KEY {A} FOREIGN KEY {B} REFERENCES R1 Переменная отношения R может быть восстановлена посредством соединения переменных отношения R1 и R2 по внешнему ключу и соотв ему первичному ключу этих переменных отношения.
Нужно стремиться к независимости отдельных проекций, т.е R1 должна не зависеть от R2 (мы могли бы разделить R1{A,B}, R2{A,C}, но в таком случае это были бы не независмые отношенияб так как мы потеряем зависимость что B -> C)
Нет смысла обязательно проводить декомпозицию до получения атомарных проекций (проекций которые уже не могут быть подвергнуты декомпозиции)
Декомпозиция должна обеспечивать сохранение зависимостей !!!
Нормальная форма Бойса-Кодда НФБК
(более строгая чем 3НФ, для случаев составных ключей)
Она определяется для данных для которых верны следующие условия:
- переменная отношения имеет 2 и больше потенциальных ключа, таких что
- Эти ключи являются составными
- Два или больше составных ключей перекрываются, т.е. имеют 1 общий атрибут.
Переменная отношения находится в нормальной форме Бойса-Кодда тогда и только тогда, когда детерминанты всех ее функц зависимостей являются потенциальными ключами. НФБК позволяют избавиться от проблем присущим в 3НФ (может присутствовать некоторая избыточность, которая приводит к проблемам insert/delete/update) и плюс то что определение не содержит ссылок на 1 и 2 нф
Например, как показано в книге, пример:
SP {S#, SNAME, P#, QTY} ключи {S#, P#} и {SNAME, P#}
находится в 3НФ, но присутствует избыточность,
S# | SNAME | P# | QTY |
-----------------------
S1 | smith | P1 | 200 |
S1 | smith | P2 | 300 |
S1 | smith | P3 | 400 |
S1 | smith | P4 | 500 |
если надо обновить имя Smith то придется найти все вхождения, или же база придет в противоречивое состояние, когда в одной строке будет S1 = Smith, а в другой S1 != Smith
лучше разбить SP на 2 проекции
- SS {S#, SNAME}
- SP {S#, P#, QTY}
или
- SS {S#, SNAME}
- SP {SNAME, P#, QTY}
Не все нужно декомпозировать. Если получаются в результате отношения в НФБК , но они становятся зависимыми, не стоит этого делать, можно считать настоящую форму атомарной.
Итак, после всего можно привести определение 3НФ (без ограничения) и НФБК Предположим что есть переменная отношения R , что Х является некоторым подмножество атрибутов этой переменной отношения R и что А является некоторым отдельным атрибутом переменной отношения R. Переменная отношения R находится в 3НФ тогда и только тогда, когда для каждой функциональной зависимости X -> A в переменной отношения R верно по крайней мере одно из следующих высказываний:
- Подмножество Х включает атрибут А (т.е функц связ тривиальна)
- Подмножество Х является суперключом переменной отношения R1
- Атрибут А входит в состав некоторого потенциального ключа переменной отношения R.
Если исключить 3 утверждение получится НФБК, которая является более строгим ограничением по сравнению с 3НФ, и является причиной ввода НФБК.
Вернемся к нашему примеру. К данному моменту мы имеем уже 8 следующиx таблиц:
haircolors=# \dt
List of relations
Schema | Name | Type | Owner
--------+---------------+-------+----------
public | address | table | postgres
public | manufacturer | table | postgres
public | order_details | table | postgres
public | orders | table | postgres
public | partner | table | postgres
public | person | table | postgres
public | product | table | postgres
public | salon | table | postgres
(8 rows)
haircolors=# \d address
Table "public.address"
Column | Type | Modifiers
----------+------------------------+-----------
id | integer | not null
city | character varying(128) | not null
building | integer | not null
flat_no | integer | not null
street | character varying(128) | not null
zip_code | integer | not null
Indexes:
"address_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "person" CONSTRAINT "fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
haircolors=# \d manufacturer
Table "public.manufacturer"
Column | Type | Modifiers
-----------------+------------------------+-----------
manufacturer_id | integer | not null
name | character varying(256) | not null
Indexes:
"manufacturer_pkey" PRIMARY KEY, btree (manufacturer_id)
Referenced by:
TABLE "product" CONSTRAINT "product_manufacturer_id_fkey" FOREIGN KEY (manufacturer_id) REFERENCES manufacturer(manufacturer_id)
haircolors=# \d order_details
Table "public.order_details"
Column | Type | Modifiers
------------------+-----------------------------+--------------------------------------------------------------------------
order_details_id | integer | not null default nextval('order_details_order_details_id_seq'::regclass)
dateorder | timestamp without time zone |
qty | integer |
Indexes:
"order_details_pkey" PRIMARY KEY, btree (order_details_id)
Referenced by:
TABLE "orders" CONSTRAINT "orders_order_details_id_fkey" FOREIGN KEY (order_details_id) REFERENCES order_details(order_details_id)
haircolors=# \d orders
Table "public.orders"
Column | Type | Modifiers
------------------+---------+-----------
id | integer | not null
product_id | integer |
partner_id | integer |
order_details_id | integer |
Indexes:
"orders_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"orders_order_details_id_fkey" FOREIGN KEY (order_details_id) REFERENCES order_details(order_details_id)
"orders_partner_id_fkey" FOREIGN KEY (partner_id) REFERENCES partner(partner_id)
"orders_product_id_fkey" FOREIGN KEY (product_id) REFERENCES product(product_id)
haircolors=# \d partner
Table "public.partner"
Column | Type | Modifiers
------------+---------+--------------------------------------------------------------
partner_id | integer | not null default nextval('partner_partner_id_seq'::regclass)
person_id | integer |
salon_id | integer |
Indexes:
"partner_pkey" PRIMARY KEY, btree (partner_id)
Foreign-key constraints:
"partner_person_id_fkey" FOREIGN KEY (person_id) REFERENCES person(person_id)
"partner_salon_id_fkey" FOREIGN KEY (salon_id) REFERENCES salon(salon_id)
Referenced by:
TABLE "orders" CONSTRAINT "orders_partner_id_fkey" FOREIGN KEY (partner_id) REFERENCES partner(partner_id)
haircolors=# \d person
Table "public.person"
Column | Type | Modifiers
-------------+------------------------+-----------
person_id | integer | not null
firstname | character varying(128) | not null
lastname | character varying(128) | not null
phonenumber | character varying(20) | not null
address_id | integer |
Indexes:
"person_pkey" PRIMARY KEY, btree (person_id)
"person_address_key" UNIQUE CONSTRAINT, btree (address_id)
Foreign-key constraints:
"fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
Referenced by:
TABLE "partner" CONSTRAINT "partner_person_id_fkey" FOREIGN KEY (person_id) REFERENCES person(person_id)
haircolors=# \d product
Table "public.product"
Column | Type | Modifiers
-----------------+------------------------+-----------
product_id | integer | not null
name | character varying(256) |
manufacturer_id | integer |
price | money |
Indexes:
"product_pkey" PRIMARY KEY, btree (product_id)
Foreign-key constraints:
"product_manufacturer_id_fkey" FOREIGN KEY (manufacturer_id) REFERENCES manufacturer(manufacturer_id)
Referenced by:
TABLE "orders" CONSTRAINT "orders_product_id_fkey" FOREIGN KEY (product_id) REFERENCES product(product_id)
haircolors=# \d salon
Table "public.salon"
Column | Type | Modifiers
------------+------------------------+----------------------------------------------------------
salon_id | integer | not null default nextval('salon_salon_id_seq'::regclass)
salon_name | character varying(128) | not null
Indexes:
"salon_pkey" PRIMARY KEY, btree (salon_id)
Referenced by:
TABLE "partner" CONSTRAINT "partner_salon_id_fkey" FOREIGN KEY (salon_id) REFERENCES salon(salon_id)
haircolors=# select * from address ;
id | city | building | flat_no | street | zip_code
----+-------------+----------+---------+-------------------------+----------
1 | Севастополь | 77 | 54 | ул. Александра Косарева | 299006
2 | Севастополь | 1 | 55 | ул. Кесаева | 299003
(2 rows)
Обратим внимание на таблицу ADDRESS, явно не находится во 2НФ, у нас присутствуют дубликаты города, если будет большая таблица, и нужно будет изменить значение города, то можно ошибиться и какая то запись станет не актуальной. Поэтому вынесем город в отдельную таблицу.
CREATE TABLE CITY (
CITY_ID SERIAL PRIMARY KEY ,
CITY_NAME VARCHAR(128)
);
INSERT INTO CITY (CITY_NAME) VALUES ('Севастополь');
haircolors=# select * from city;
city_id | city_name
---------+-------------
1 | Севастополь
(1 row)
Добавим столбец address.city_id как внешний ключ ссылку на city.city_id. Обновим записи таблицы ADDRESS и удалим затем столбец CITY.
ALTER TABLE address ADD COLUMN city_id INT REFERENCES city(city_id);
UPDATE address SET city_id=1;
ALTER TABLE address DROP COLUMN city;
haircolors=# \d address
Table "public.address"
Column | Type | Modifiers
----------+------------------------+-----------
id | integer | not null
building | integer | not null
flat_no | integer | not null
street | character varying(128) | not null
zip_code | integer | not null
city_id | integer |
Indexes:
"address_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"address_city_id_fkey" FOREIGN KEY (city_id) REFERENCES city(city_id)
Referenced by:
TABLE "person" CONSTRAINT "fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
haircolors=# select * from address ;
id | building | flat_no | street | zip_code | city_id
----+----------+---------+-------------------------+----------+---------
1 | 77 | 54 | ул. Александра Косарева | 299006 | 1
2 | 1 | 55 | ул. Кесаева | 299003 | 1
(2 rows)
Все, дубликатов нет, таблица соответствует 2НФ, можно вспомнить, что в реальном мире существует связь - одному почтовому индексу соответствует четкий перечень некоторых улиц, следовательно у нас существует транзитивная связь между столбцами street и zip_code, а именно - мы можем вычислить zip_code по street, типа того как мы бы открыли справочник, нашли свою улицу и соответствующий ей индекс.
Это я думаю наглядный пример приведения к 3НФ, мы нашли транзитивную связь и пытаемся избавиться от нее (поправьте если я неправ).
Создадим таблицу почтовых индексов и справочник почтовых индексов:
CREATE TABLE ZIP_CODE (
ZIP_CODE INT PRIMARY KEY
);
INSERT INTO ZIP_CODE (ZIP_CODE) VALUES (299006);
INSERT INTO ZIP_CODE (ZIP_CODE) VALUES (299003);
haircolors=# select * from zip_code;
zip_code
----------
299006
299003
(2 rows)
Положительный момент, теперь мы имеем список индексов и можем добавить новый индекс без проблем, ранее же мы могли указать индекс только в составе существующего адреса. Плюс мы контролируем целостность, т.е. мы не сможем добавить 2 одинаковых почтовых индекса в таблицу.
haircolors=# \d zip_code
Table "public.zip_code"
Column | Type | Modifiers
----------+---------+-----------
zip_code | integer | not null
Indexes:
"zip_code_pkey" PRIMARY KEY, btree (zip_code)
Referenced by:
TABLE "zip_code_catalog" CONSTRAINT "zip_code_catalog_zip_code_fkey" FOREIGN KEY (zip_code) REFERENCES zip_code(zip_code)
Предположим что не бывает 2 одинаковых улицы в городе, тогда значение название улицы уникально:
CREATE TABLE ZIP_CODE_CATALOG (
STREET VARCHAR(128) PRIMARY KEY,
ZIP_CODE INT REFERENCES ZIP_CODE(ZIP_CODE)
);
INSERT INTO ZIP_CODE_CATALOG (STREET, ZIP_CODE) VALUES (
'ул. Александра Косарева', 299006);
INSERT INTO ZIP_CODE_CATALOG (STREET, ZIP_CODE) VALUES (
'ул. Кесаева', 299003);
haircolors=# select * from zip_code_catalog ;
street | zip_code
-------------------------+----------
ул. Александра Косарева | 299006
ул. Кесаева | 299003
(2 rows)
haircolors=# \d zip_code_catalog
Table "public.zip_code_catalog"
Column | Type | Modifiers
----------+------------------------+-----------
street | character varying(128) | not null
zip_code | integer |
Indexes:
"zip_code_catalog_pkey" PRIMARY KEY, btree (street)
Foreign-key constraints:
"zip_code_catalog_zip_code_fkey" FOREIGN KEY (zip_code) REFERENCES zip_code(zip_code)
Теперь поправим таблицу ADDRESS:
Удалим столбец zip_code, он нам уже не нужен:
ALTER TABLE address DROP COLUMN zip_code ;
Добавим ограничение на столбец street пусть он будет внешним ключом ссылающимся на первичный ключ zip_code_catalog.street
ALTER TABLE address ADD FOREIGN KEY (street) REFERENCES zip_code_catalog(street);
Выглядит теперь таблица ADDRESS так:
haircolors=# \d address
Table "public.address"
Column | Type | Modifiers
----------+------------------------+-----------
id | integer | not null
building | integer | not null
flat_no | integer | not null
street | character varying(128) | not null
city_id | integer |
Indexes:
"address_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"address_city_id_fkey" FOREIGN KEY (city_id) REFERENCES city(city_id)
"address_street_fkey" FOREIGN KEY (street) REFERENCES zip_code_catalog(street)
Referenced by:
TABLE "person" CONSTRAINT "fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
Мы избавились от столбца zip_code и качество управления целостностью данных возросло. Мы теперь можем пополнять список почтовых индексов, где автоматически контролируется уникальность, мы также добились независимости почтового индекса от других данных.
Мы создали справочник улиц принадлежащих какому то из почтовых индексов, опять же, контролируем название улицы, мы не сможем добавить 2 одинаковые улицы с какими то индексами в справочник zip_code_catalog (мы условились, что 1 улице можно присвоить 1 уникальный индекс)
haircolors=# select * from address ;
id | building | flat_no | street | city_id
----+----------+---------+-------------------------+---------
1 | 77 | 54 | ул. Александра Косарева | 1
2 | 1 | 55 | ул. Кесаева | 1
(2 rows)
На этом можно считать пример приведения ADDRESS к 3НФ успешным, мы поступили практически подобно примеру разделив данные. Остальные данные находятся в 3НФ, мы видим насколько мы декомпозировали исходную таблицу, создав некоторое количество таблиц.
haircolors=# select * from manufacturer ;
manufacturer_id | name
-----------------+--------
1 | Matrix
2 | Loreal
3 | Blond
4 | Союз
(4 rows)
haircolors=# select * from order_details;
order_details_id | dateorder | qty
------------------+---------------------+-----
1 | 2017-07-03 12:15:01 | 3
2 | 2017-07-03 12:16:01 | 2
3 | 2017-07-02 11:01:01 | 12
4 | 2017-07-02 11:01:01 | 120
(4 rows)
haircolors=# select * from orders;
id | product_id | partner_id | order_details_id
----+------------+------------+------------------
5 | 1 | 1 | 1
6 | 1 | 2 | 1
7 | 1 | 3 | 1
8 | 2 | 1 | 2
9 | 2 | 2 | 2
10 | 2 | 3 | 2
11 | 3 | 4 | 3
12 | 3 | 5 | 3
13 | 3 | 6 | 3
14 | 4 | 4 | 4
15 | 4 | 5 | 4
16 | 4 | 6 | 4
(12 rows)
haircolors=# select * from partner;
partner_id | person_id | salon_id
------------+-----------+----------
1 | 1 | 1
2 | 1 | 2
3 | 1 | 4
4 | 2 | 3
5 | 2 | 4
6 | 2 | 5
(6 rows)
haircolors=# select * from person ;
person_id | firstname | lastname | phonenumber | address_id
-----------+-----------+----------+--------------+------------
1 | Денис | Петров | +79784567897 | 1
2 | Юлия | Бабкина | +79784168585 | 2
(2 rows)
haircolors=# select * from product ;
product_id | name | manufacturer_id | price
------------+-----------------------+-----------------+------------
1 | Краска для волос | 1 | 899.01 руб
2 | Краска для волос | 2 | 599.12 руб
3 | Краска для волос | 3 | 299.12 руб
4 | Полотенца одноразовые | 4 | 199.12 руб
(4 rows)
Tаблицу SALON которая находится в НФБК в дальнейшем можно декомпозировать к 1 столбцу, который и будет являться первичным ключом, маловерятно что может понадобиться иметь 2 одинаковых имен салонов, но я оставляю уникальность по цифровому первичному ключу, так как удобнее работать. Хотя это и некоторая избыточность.
haircolors=# select * from salon;
salon_id | salon_name
----------+------------
1 | Е-Студия
2 | Ле-туаль
3 | UpDo
4 | ViVa
5 | Diana
(5 rows)
Как видно, 3НФ достаточна чтоб избавиться от избыточности, которая может приводить к проблемам обновления, но изза того что данные разъединены теперь немного сложнее представить полную картину, попробуем нарисовать диаграмму нашей базы данных
Я попробовал несколько продуктов, например draw.io, но остановился на DBDesigner, мне понравилось, бесплатный, быстро и красиво.
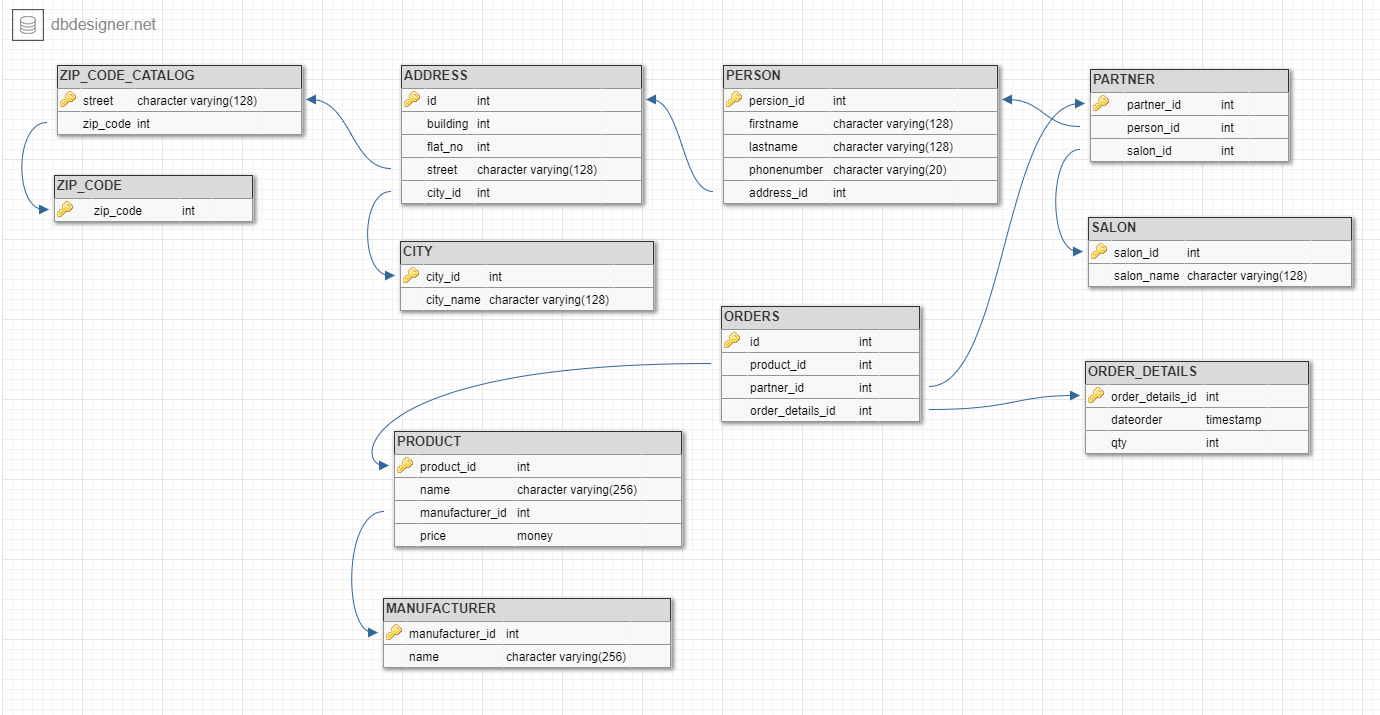
Теперь связи стали нагляднее, после визуализации стало намного проще воспринять зависимости (ключик означает первичный ключ PRIMARY KEY, стрелка от значения на диаграмме означает что данный столбец это внешний ключ FOREIGN KEY, ссылающийся на один из первичных ключей).
Немного жаль что никак специально не отображается визуально связь ОДИН К ОДНОМУ, например у нас такая связь обозначена между таблицами PERSON и ADDRESS для поля address_id в таблице PERSON мы включили уникальность, и в редакторе тоже это указано, но графически это ничем не отличается от изображения FOREIGN KEY.
Напомню как выглядит связь ОДИН К ОДНОМУ:
haircolors=# \d person
Table "public.person"
Column | Type | Modifiers
-------------+------------------------+-----------
person_id | integer | not null
firstname | character varying(128) | not null
lastname | character varying(128) | not null
phonenumber | character varying(20) | not null
address_id | integer |
Indexes:
"person_pkey" PRIMARY KEY, btree (person_id)
"person_address_key" UNIQUE CONSTRAINT, btree (address_id)
Foreign-key constraints:
"fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
Referenced by:
TABLE "partner" CONSTRAINT "partner_person_id_fkey" FOREIGN KEY (person_id) REFERENCES person(person_id)
как видно мы добавили уникальность внешнему ключу address_id, и теперь адрес из таблицы address может быть назначен только одному уникальному человеку. Два разных человека не смогут иметь один и тот же адрес.
haircolors=# \d address
Table "public.address"
Column | Type | Modifiers
----------+------------------------+-----------
id | integer | not null
building | integer | not null
flat_no | integer | not null
street | character varying(128) | not null
city_id | integer |
Indexes:
"address_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"address_city_id_fkey" FOREIGN KEY (city_id) REFERENCES city(city_id)
"address_street_fkey" FOREIGN KEY (street) REFERENCES zip_code_catalog(street)
Referenced by:
TABLE "person" CONSTRAINT "fk_address_id" FOREIGN KEY (address_id) REFERENCES address(id)
Связь ОДИН КО МНОГИМ
В нашем случае связи созданные как внешний ключ ссылающийся на первичный ключ и являются отражением связи ОДИН КО МНОГИМ. Например поле zip_code в zip_code_catalog является внешним ключом ссылающимся на уникальный ключ (первичный ключ) таблицы zip_code. Чем мы собственно хотим указать в таблице zip_code_catalog, что несколько уникальных улиц могут ссылаться на один и тот же индекс. (один и тот же индекс -> много улиц).
haircolors=# \d zip_code
Table "public.zip_code"
Column | Type | Modifiers
----------+---------+-----------
zip_code | integer | not null
Indexes:
"zip_code_pkey" PRIMARY KEY, btree (zip_code)
Referenced by:
TABLE "zip_code_catalog" CONSTRAINT "zip_code_catalog_zip_code_fkey" FOREIGN KEY (zip_code) REFERENCES zip_code(zip_code)
haircolors=# \d zip_code_catalog
Table "public.zip_code_catalog"
Column | Type | Modifiers
----------+------------------------+-----------
street | character varying(128) | not null
zip_code | integer |
Indexes:
"zip_code_catalog_pkey" PRIMARY KEY, btree (street)
Foreign-key constraints:
"zip_code_catalog_zip_code_fkey" FOREIGN KEY (zip_code) REFERENCES zip_code(zip_code)
Referenced by:
TABLE "address" CONSTRAINT "address_street_fkey" FOREIGN KEY (street) REFERENCES zip_code_catalog(street)
Связь МНОГИЕ КО МНОГИМ
В нашем случае это таблицы PARTNER и ORDERS. В таблице PARTNER мы таким образом выражаем ситуацию что много PERSON могут быть поставщиками SALON, т.е. другими более человечными словами - любой человек может поставлять товары в любой салон. И в этой таблице мы отображаем что человек с PERSON_ID является поставщиком какого то салона с SALON_ID, т.е фактически партнер.
Cвязь МНОГИЕ КО МНОГИМ образуется через связующую таблицу, которой является в данном случае partner.
haircolors=# \d partner
Table "public.partner"
Column | Type | Modifiers
------------+---------+--------------------------------------------------------------
partner_id | integer | not null default nextval('partner_partner_id_seq'::regclass)
person_id | integer |
salon_id | integer |
Indexes:
"partner_pkey" PRIMARY KEY, btree (partner_id)
Foreign-key constraints:
"partner_person_id_fkey" FOREIGN KEY (person_id) REFERENCES person(person_id)
"partner_salon_id_fkey" FOREIGN KEY (salon_id) REFERENCES salon(salon_id)
Referenced by:
TABLE "orders" CONSTRAINT "orders_partner_id_fkey" FOREIGN KEY (partner_id) REFERENCES partner(partner_id)
Выводы
Цель нормализации - избавиться от избыточности, и избежать аномалий обновления к которым приводит избыточность.
Каждая переменная отношения на некотором уровне нормализации соответствует условиям более низких уровней нормализации. (переход ко 2й форме возможен если отношение приведено к 1й форме)
Всегда можно выполнить приведение к НФБК.
Процесс нормализации заключается в замене переменной отношения некоторым набором ее проекций, составленных таким образом, чтобы обратное соединение этих проекций позволяло вновь получить исходную переменную отношения. (т.е. это обратимый процесс, декомпозиция выполняется без потери информации) Нужно разбивать на независимы проекции (независимые одна от другой), тогда это будет декомпозиция с сохранением зависимостей.
На этом я хочу закончить данную статью. В следующей заметке я добавлю очень краткое описание следующих нормальных форм 4НФ, 5НФ и немного понятий о денормализации, а также алгоритм приведения к НФБК.
Я действительно на примерх увидел, как нормализация уменьшает избыточность базы данных и препятствует внесению случайных ошибок.
Авторы отмечают, что есть более высокие строгие нормальные формы, но на практике обычно используются только первые три. Возможно они и правы, так как допустим 3НФ требует разьеденить почти все составляющие адреса, но если адрес не меняется часто, то чтоб сформировать полную информацию о полях адреса, нам уже как минимум нужно обратиться к нескольким таблицам, что возможно может послужить причиной проблем быстродействия.
Comments
comments powered by Disqus